Bók þessi varð til eftir að höfundur hafði kennt vefforritun við HÍ í nokkur ár án þess að hafa fundið hentuga kennslubók. Markmið bókarinnar er að veita inngang að vefforritun án nokkurrar reynslu af forritun, ásamt því að fara yfir breiddina11 ólíkt því að fara á dýptina, gert er ráð fyrir að lesandi leiti sér frekari þekkingar og vinni verkefni til að byggja dýpri kunnáttu á efninu. á því sem vefforritun er. Eftir að hafa farið í gegnum efnið ættir þú að hafa þekkingu til þess að byggja vefi með HTML, CSS og JavaScript.
Verandi bók um vefforritun eru tenglar mikið notaðir til að vísa fram og til baka og útum allt í ítarefni og þess háttar. Ekki er þörf á að lesa allt ítarefni sem vísað er í, en það getur hjálpað við að byggja upp dýpri skilning á efninu. Reynt er eins og hægt er að nota íslensk orð yfir hugtök þar sem þau eru til. Stuðst er við Íðorðabanka Árnastofnunnar, sérstaklega Tölvuorðasafnið (5. útgáfa 2013) eða íslenskun höfundar.
0.1 Hugtök
Þar sem þessi bók gerir ekki ráð fyrir neinni fyrri reynslu í forritun er vert að fara lauslega yfir nokkur grunnhugtök áður en lagt er af stað.
0.1.1 Talnakerfi & tölvur
Talnakerfi er kerfi sem notar tölustafi með tölustöfum. Tölvur telja
yfirleitt ekki með tugakerfi22
eða tíundakerfi, kerfi sem hefur 10 sem
grunntölu og notar tölustafina
0–9.
(e. decimal) eins og í flestum daglegum athöfnum, heldur nota tölvur
oftast tvíundakerfi (e. binary): talnakerfi sem hefur grunntöluna
2. Þá eru aðeins tölurnar 0 og
1 notaðar til að tákna allar tölur. Einfölduð
ástæða fyrir þessu er að þessi gildi tákna annað hvort
á eða af stöður sem hentar
tölvum vel.
Einnig kemur fyrir að áttundakerfi (e. octal) og sextándakerfi (e.
hexadecimal, oft stytt í hex) séu notuð, þau virka á sama
grundvelli. Áttundakerfi notar 0 til 7 til
að tákna allar tölur, en sextándakerfi 0 til
9 ásamt a, b, c,
d, e og f fyrir tölurnar 10
til 15, engin munur er á því hvort notaðir séu lág- eða hástafir en
gæti ætti samræmis.
Ef við erum að vinna með mörg talnakerfi skráum við grunntöluna með
undirskrift við töluna sem við erum að vinna með, t.d.
10₂ fyrir tvíundakerfi eða 1₁₀ fyrir
tugakerfi. Einnig eru forskeyti33
forskeyti (e. prefix) (eða fortáknun) er þegar einhverju
er skeytt fyrir framan, eftirtáknun (e. postfix) er þegar
skeytt er fyrir aftan.
stundum notuð: 0b fyrir tvíunda, 0o fyrir
áttunda, og 0x fyrir sextánda.
Til að breyta tölu úr talnakerfi yfir í tugakerfi margföldum við
grunntöluna með hækkandi veldi af grunntölunni frá hægri til
vinstri, byrjað á 0, t.d.
0001₂ = 0b0001 = 2³ * 0 + 2² * 0 + 2¹ * 0 + 2⁰ * 1 |
|
= 1₁₀ |
|
1011₂ = 0b1011 = 2³ * 1 + 2² * 0 + 2¹ * 1 + 2⁰ * 1 |
|
= 8 + 0 + 2 + 1 |
|
= 11₁₀ |
|
1337₈ = 0o1337 = 8³ * 1 + 8² * 3 + 8¹ * 3 + 8⁰ * 7 |
|
= 512 + 192 + 24 + 7 |
|
= 735₁₀ |
|
bad₁₆ = 0xBAD = 16² * 11 + 16¹ * 10 * 16⁰ * 13 |
|
= 2816 + 160 + 13 |
|
= 2989₁₀ |
0.1.2 Bitar & bæti
Biti (e. bit, stytting á binary digit44
eða réttara sagt
portmanteau.) er gildi sem tekur annaðhvort af eða á stöðu og er oftast táknað
með 0 eða 1, af eða
á, true eða false.
Bæti (e. byte)
er hópur af (oftast!) átta bitum sem getur túlkað
2⁸ = 256 gildi. Fyrir stærð á hlutum í tölvum eru
notaðar tvær mismunandi túlkanir:
-
Tíundatúlkun á bætum með
SI forskeyti, t.d.
1 kB = 1000 byte(kilobyte) eða1 MB = 1000² byte(megabyte) -
Tvíundatúlkun á bætum með
IEC forskeyti, t.d.
1 KiB = 1024 byte(kibibyte) eða1 MiB = 1024² byte(mebibyte)
Ástæðan fyrir þessum mun eru líklega sú að fólk sem vinnur með
raunverulega hluti (t.d. rafmagnsverkfræðingar sem hanna
vélbúnað) hugsa og vinna almennt í tugakerfi en tölvunarfræðingar í
tvíundakerfi. Þetta er líka ástæða þess að ef keyptur er harður
diskur sem geymir 1 TB af gögnum geymir hann í raun og
veru 1000⁴ byte sem eru
1000⁴/1024⁴ = 0,9095 TiB = 931,323 GiB.
0.1.3 GUI & CLI
Til þess að eiga í samskiptum við tölvur notum við jaðartæki55 jaðartæki (e. peripheral device) er tæki (t.d. mús eða lyklaborð) sem er tengt við tölvu og leyfir okkur að koma upplýsingum inn í hana., og með þeim komum við skipunum inn í tölvuna í gegnum skel66 því þetta er ysta lag stýrikerfisins. (e. shell). Skelin getur annaðhvort verið grafísk eða byggð á texta.
GUI (Graphical user interface) forrit, eru forrit með grafísku notendaviðmóti: við sjáum uppsett viðmót með myndum, texta, litum og þannig. Við notum þessi forrit yfirleitt með því að smella á viðeigandi hluta viðmóts (með t.d. mús, fingri, eða öðru jaðartæki) og skrifa inn texta. Dæmi um GUI forrit sem við notum mikið í vefforritun eru vafri og textaritill.
CLI
(Command-line interface)
forrit, eru forrit sem aðeins byggja á texta. Við skrifum inn texta
í túlk, skipanalínu (e. command-line), fyrir skelina og fáum til
baka línur af texta. Engar myndir eru notaðar (nema þær séu myndaðar
með texta, oft kallað ascii art) en litaður texti er
möguleiki. Í Windows er hægt að nota
cmd.exe.
zsh
í macOS (í gegnum
Terminal), og
Bash
á Linux.
0.1.4 Textaritlar
Þegar við vinnum með texta (texta í sínu hreinasta formi, stafir án nokkurs útlits) notum við yfirleitt textaritla. Textaritlar geta verið frá mjög einföldum forritum (t.d. Notepad í Windows) yfir í flókin forrit sem hafa verið til í tugi ára (t.d. Vi og Emacs). Yfirleitt er best að lenda einhversstaðar í miðjunni, með textaritli sem auðvelt er að byrja að nota, en hægt er að bæta við virkni og læra betur á með tímanum.
Textaritlar sem vinsælir eru í dag og mælt er með eru t.d.: Visual Studio Code, frír ritill frá Microsoft; eða Sublime Text, eldri ritill sem getur verið hraðari í stærri verkefnum og í því að vinna með stærri skrár.
Visual Studio Code er smíðaður með veftækni—allt viðmót er útbúið með HTML, CSS og JavaScript! Mjög líklega er það ástæða þess að erfitt getur verið að vinna með stór verkefni eða stórar skrár í þeim.
0.1.5 Stafasett
Til þess að vinna með stafi og texta í tölvum þarf á einhvern hátt að skilgreina hvernig þeir eru geymdir. Þar sem tölvur vinna helst með tvíundakerfi, eru þau kerfi möppun88 möppun (eða vörpun) er hugtak úr stærðfræði, þar sem föll varpa gildum á milli setta. Í forritun er þetta hugtak oft notað þar sem verið er að vinna með gögn, t.d. möppun á kennitölu yfir í einstakling. á tölu yfir í staf og öfugt. Við það að skrifa staf breytir ritill eða forrit stafnum í viðeigandi tölu í því skjali sem geymir textann.
Með fyrstu stafasettum sem skilgreind voru fyrir tölvur var ASCII
(American Standard Code for Information Interchange) sem byggt var á
hvernig skipst var á upplýsingum með símskeytum. Í ASCII eru sjö
bitar notaðir til að túlka 128 stafi, fyrstu 32 eru
stýristafir (e. control characters), stafir sem ekki eiga
að birtast (t.d. er 1010₂ notað til að túlka bil),
næstu 105 stafir kóða greinarmerki, tölustafi og 26 stafi
enskastafrófsins (bæði há- og lágstafi).
Þegar við vinnum með texta í forritun getur það komið fyrir að við
viljum birta tákn sem hefur ákveðna virkni í forritunarmálinu. Þá
getum við notað lausnarstaf (e. escape character) til að
skilgreina lausnarrunu (e. escape sequence) fyrir stafinn.
T.d. eru enskar gæsalappir (") oft notaðar til að
merkja streng (e. string), texta sem birta á, og
\ notaður sem lausnarstafur. Þá getum við búið til
lausnarrununa \" innan strengs til að birta
":
"Strengur sem inniheldur ekki gæsalappartákn" |
|
"Strengur sem inniheldur gæsalappartákn með lausnarrunu: \"" |
|
"Ógildur strengur sem inniheldur " gæsalappartákn" |
Af greinarmerkjum eru nokkur sem við þurfum að vita nokkuð nákvæm skil á:
-
Bil (e. space), stafakóði
0x20eða20₁₀, myndaður með að ýta á bilstöngina (e. spacebar). Greinarmerki sem skiptir orðum. -
Tab, stafakóði
0x09eða9₁₀, oft táknað með lausnarrununni\t. Myndað með því að ýta á dálkahnappinn (e. tab key), oftast merktur með⇥. Stýritákn sem færir línu að næsta dálkahaki (e. tab stop). -
Nýlína (e. newline), stafakóði
0x0Aeða10₁₀, oft táknað með lausnarrununni\n,EOL(end of line), eðaLF(line feed). Myndað með því að ýta á vendihnappinn (e. enter key), oftast merktur með↵. Stýritákn sem skilgreinir nýja línu í texta. -
Vendistafur99
bókstaflega frá því þegar færa þurfti stöng aftur í byrjun línu á
ritvélum fyrir hverja línu.
(e.
carriage return), stafakóði
0x0Deða13₁₀, oft táknað með lausnarrununni\r, eðaCR(carriage return).
Öll þessi greinarmerki falla undir að vera whitespace1010 auglýst er eftir íslensku orði fyrir whitespace. tákn (eða stýristafir), þau skilgreina lóðrétt og lárétt bil í texta, og eru í langflestum tilfellum ósýnileg. Í forritun geta þau skipt máli.
Það er mismunandi milli stýrikerfa hvort þetta tákn sé myndað þegar
ýtt er á vendihnappinn. Windows táknar nýjar línur með bæði nýlínu
og vendistaf: CRLF eða \r\n, en
Unix kerfi (þ.m.t. Linux og macOS) nota aðeins nýlínu:
LF eða \n. Þetta getur valdið vandræðum
þegar unnið er með textaskrár á milli stýrikerfa.
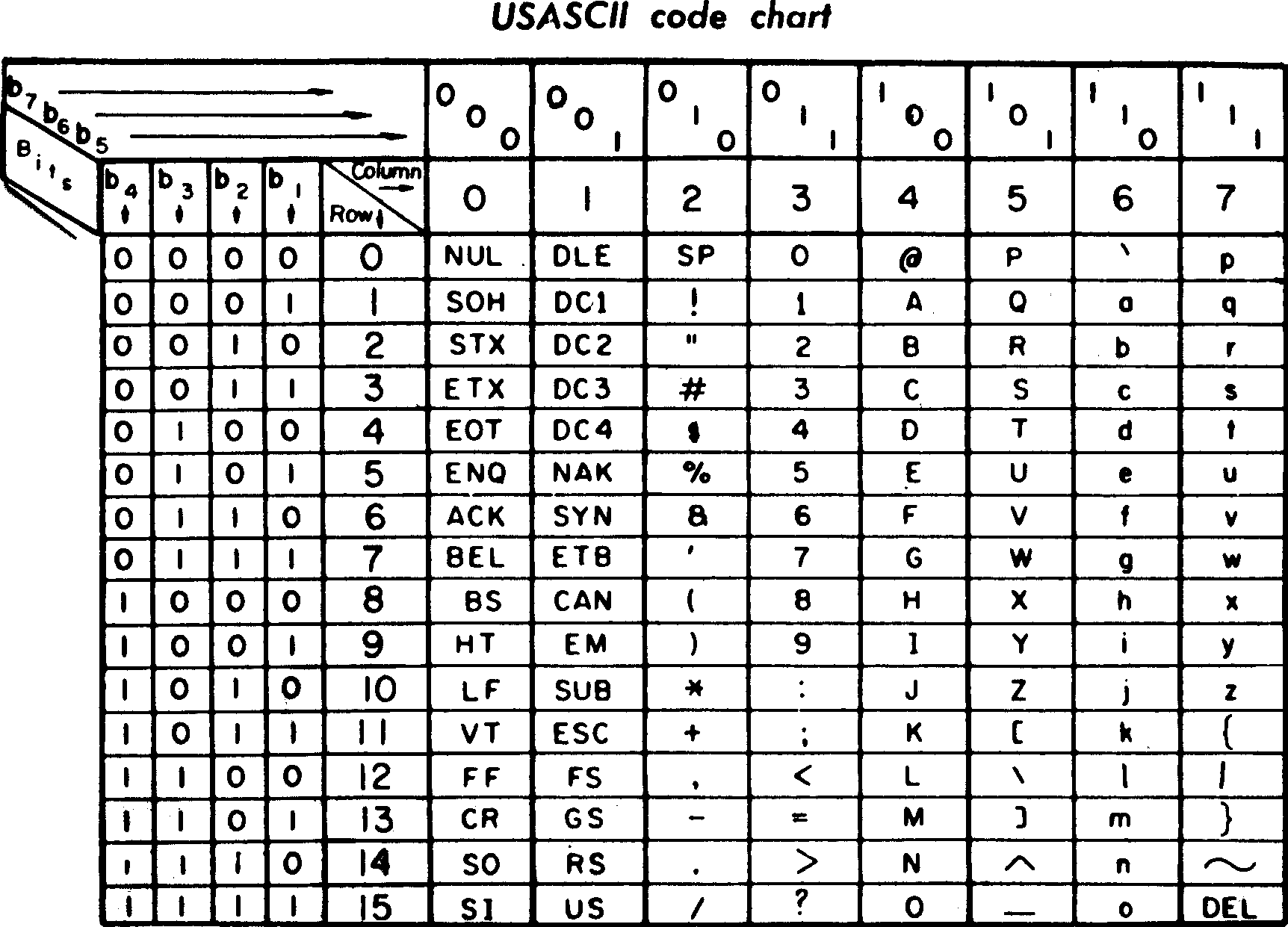
Tafla til uppflettingar á US-ASCII kóðum, frá ca. 1970.
Þegar tölvur fóru að vera notaðar utan Bandaríkjanna og þar sem fleiri stafir eru notaðir, voru fundin upp ný stafasett. Fyrir latneska stafrófið voru ISO-8859-1 og Windows-1252 mest notuð á vefnum, þar sem þau gat kóðað allt stafrófið í einu bæti per staf.
Til þess að koma í veg fyrir að hvert stafróf þyrfti sitt eigið stafasett og allan ruglingin tengdan því, var Unicode staðallinn búinn til, með það að markmiði að túlka öll stafróf jarðar ásamt öðrum sértækum stöfum (t.d. tjákn—emoji tákn). UTF-8 er stafasett sem kóðar alla stafi í Unicode og notar til þess allt að fjögur bæti. Fyrstu 128 stafir í UTF-8 eru þeir sömu og í ASCII, þannig að hægt er að opna ASCII skjöl sem UTF-8 án ruglings.
Á vefnum er UTF-8 langmest notaða stafasettið og það sem við notum.
Textaritillinn sem við notum ætti að sýna okkur í hvaða stafasetti
skjalið okkar er og leyfa okkur að breyta því. Ef við lendum í því
að vista efni í textaritli en vafri birtir textann brenglaðan (sér í
lagi íslenska stafi, t.d. halló þið sem er textinn
halló þið vistaður í UTF-8 en birtur sem ISO-8859-1) er
það vegna mismunar á stafasetti sem skjal er vistað í, og þess sem
vafri birtir. Það er ekki hægt að greina 100% sjálfkrafa í hvaða
stafasetti skjal eða vefsíða er í, við verðum að gera það sjálf til
að koma í veg fyrir mögulega brenglun.
0.2 Dæmi og textar
0.2.1 example.org
Í dæmum þar sem vísað er í vefþjóna og sá vefþjónn sem um ræðir
skiptir ekki máli, er hægt að nota example.com,
example.org eða example.net. Þessi
lénsnöfn eru sérstaklega tekin frá til notkunar í dæmum.
Það þýðir að enginn vaktar þau eða tekur við gögnum sem send eru á
þau (ólíkt t.d. test.is eða example.is sem
eru í eigu einhverra!)
0.2.2
foo & bar
„Orðin“ foo og bar eiga eflaust eftir að
skjóta upp kollinum þegar verið er að læra vefforritun. Þegar verið
er að skrifa dæmi þar sem einhver texti eða heiti á breytu þarf að
koma fram, en heitið sjálft skiptir ekki máli, eru
foo og bar (einnig foobar og
baz) oft notuð.
Dæmi í JavaScript þar sem foo og bar eru
notuð til að sýna samlagningu á tveim breytum, heiti breytanna
skiptir engu máli.
const foo = 1;
|
|
const bar = 2;
|
|
console.log(foo + bar);
|
There are only two hard things in Computer Science: cache invalidation and naming things.
Að nota þessi heiti fyrir breytur á sér langa sögu, allt frá sjöunda áratugnum og jafnvel alla leið til seinni heimstyrjaldarinnar með skammstöfuninni FUBAR.
Þó svo að þessi breytu heiti hafi lengi verið notuð til að sýna fram á virkni, þýðir það ekki að þetta sé góð hefð. Að nota abstrakt dæmi, ótengda raunveruleikanum hjálpar ekki til við að læra hvernig hlutir virka, höfundur reynir að halda sig frá þessu í dæmum eins og hægt er.
0.2.3 Lorem ipsum
Annar „gervitexti“ sem skýtur upp kollinum er lorem ipsum, sem er texti sem einnig á sér langa sögu en á prenti. Þegar við vinnum útlit þurfum við oft að hafa mikið af texta til þess að sjá hvernig það mun haga sér. Þá er oft ekki búið að semja lokatextann og er þá lorem ipsum notað. Þessi texti er skemmd útgáfa af latneskum texta sem hefur verið notuð síðan a.m.k. 1960.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.